Summary
Kumo partnered with a rapidly expanding social commerce marketplace, to generate personalized recommendations for an in-product carousel of items. Due to the unique nature of the customer’s business, numerous technical obstacles to produce high-quality personalized recommendations were overcome. These hurdles include extensive inventories consisting of millions of item listings, item uniqueness (when an item is sold, it is gone), and unstructured user-generated descriptions. Kumo’s platform enabled a single data scientist to build graph neural network (GNN)-powered personalized recommendations in weeks, showing 20% improvement in model performance over a content-based approach that did not leverage graph signals. The end-to-end system was deployed to production using Kumo, Snowflake, DBT, Dagster.
About the customer
The customer is a rapidly expanding livestream and social commerce marketplace offering a diverse range of unique, sought-after, and high-value items. Its platform specializes in providing access to rare collectibles, pop culture merchandise, and luxury fashion pieces.
Use case
The customer was developing a new in-product carousel to make personalized recommendations of “similar items that the user might be interested in”, with dual objectives of enhancing user discovery and increasing cross-selling opportunities.
Technical challenges
Due to the unique nature of the customer’s business, as a livestream marketplace of hard-to-get items, most traditional recommendation algorithms do not work. There are three key factors that make traditional methods for personalized recommendations a fruitless endeavor: unique, 1-time listings, extensive inventory, and unreliable product descriptions.
Unique 1-time listings
Items featured on the platform are unique and once sold, removed from inventory. This unique characteristic poses a challenge for conventional collaborative filtering methods in recommendation systems, as individual items lack historical sales data. Additionally, the dynamic nature of inventory turnover hinders the algorithm’s ability to predict user preferences and recommend relevant items for personalized recommendations.
Extensive inventory selection
As a growing platform, there are millions of active items in inventory, all of which are eligible for recommendation at any time. Generating personalized recommendations for millions of items can be computationally expensive, often requiring help from infrastructure teams to build and maintain complex systems, such as a two-phase retrieval + re-ranker architecture.
Unstructured and unreliable item descriptions
Item descriptions are entirely user-generated and frequently lack completeness, or are filled with attention-grabbing words or characters rather than accurate product descriptions. As a result, it is difficult to extract meaningful signals about each item.
Predictive query
In order to generate high-quality, item-to-item personalized recommendations and maximize gross merchandise value (GMV), the customer used Kumo to train a graph neural network (GNN) model optimized for co-purchases, which are items bought together within a short time range. While Kumo offers many options, this specific optimization objective was best aligned with the goals of the customer’s new product surface, the in-product carousel, as it helps users discover products in adjacent sub-categories that they are likely to purchase, leading to a more diverse-looking product carousel, and ultimately aligning with the business goal of maximizing GMV.
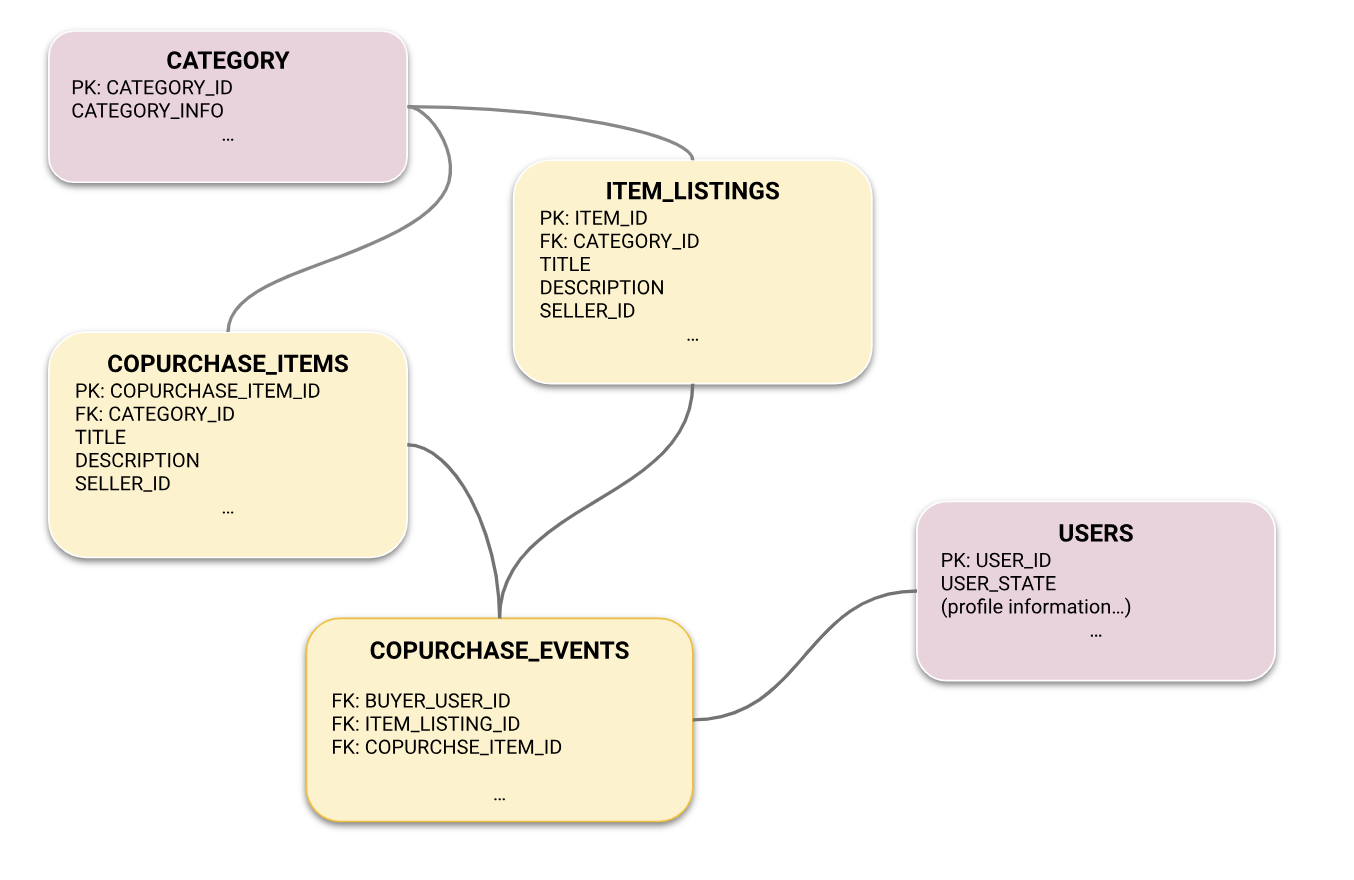
First, the customer connected its Snowflake tables to Kumo. The tables contain a combination of content-based signals, and user-behavioral signals that lay the foundation for generating personalized recommendations. This included:
- information about individual product listings (description, price, product details)
- the product taxonomy
- attributes about users such as location
- past purchases made by users
which were pre-processed with a Kumo view to generate co-purchases events. Once the tables were connected within Kumo, they were automatically assembled into a graph:
Using this graph, the data scientist used Kumo’s Predictive Query Language (PQL) to define the machine learning task for personalized recommendations, as follows:
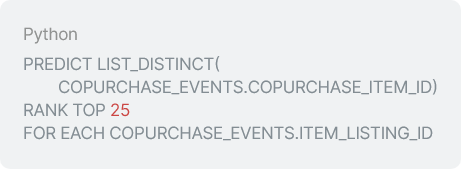
Compared to the complexities and challenges of traditional collaborative filtering methods, which often involve intricate data preprocessing and model tuning, PQL offers a streamlined approach. It allows data scientists to easily convert business questions into predictive AI models with straightforward, intuitive queries. This simplicity not only accelerates the development process of personalized recommendations but also reduces the potential for errors and inefficiencies.
Once the predictive query is trained, it can generate batch predictions on a recurring basis. The output of this specific query was a new Snowflake table, containing the top 25 COPURCHASE_ITEM_ID that a user would be most likely to purchase, for each item ITEM_ID in the ITEM_LISTINGS table at the time of batch prediction. This is the prediction for the personalized recommendation.
Model architecture
Kumo’s GNN delivered great model performance, and overcame the technical challenges unique to the customer’s business when generating personalized recommendations.
Unique 1-time listings
Inductive GNN architecture
Because each item in the inventory is unique, the customer needs to use an inductive GNN architecture, or one that is optimized for making predictions on “cold start” items, or items with no sales or interaction history. This was done by adjusting the the following options in Kumo’s model planner:
- handle_new_target_entities: This flag enabled an inductive GNN architecture, as opposed to a transductive one, which was the default.
- max_target_neighbors_per_entity: Setting this to zero prevented the GNN from using input features that were not available for cold-start items.
- output_embedding_dim: This was increased to 128 to improve representation power of the item embeddings in the GNN model.
Filter out “sold” items
At prediction time, a SQL view makes sure that the personalized recommendations does not include items that have already been sold. Kumo’s GNN neighborhood sampler can also exclude out-of-stock items at training time, if the user configures the end_time column on the item table.
Extensive inventory selection
Optimized Batch Prediction
Because the customer has millions of active items, cost and performance are top-of-mind. Leveraging approximate-nearest-neighbor algorithms on top of graph embeddings, Kumo’s batch prediction pipeline supports inventory sizes of at least ten million items. This customer produced batch recommendations for the entire inventory in less than an hour. For more information, you can read about Kumo’s data scale limits.
Unstructured and unreliable item descriptions
Language Models
The customer needs to identify and leverage the valuable information hidden within the user-created product descriptions. To achieve this, they employed a language model to create text embeddings. Kumo supports a variety of open source and commercial large language models, enabling unstructured text to be used directly by the GNN training process. The customer chose the open source GloVe embeddings with a dimension size of 50. Models such as distilroberta and text-embedding-3 are also available in Kumo.
The outcome: personalized recommendation model performance was 20% better
The Kumo model showcased 20% better model performance for personalized recommendations when compared to a relatively strong baseline model that only used content-based signals (specifically text embeddings), without any graph-based signals. Performance was measured by MAP@10, Recall@5 on a holdout dataset. Kumo achieved the lift in predicting personalized recommendations because GNNs can combine content-based signals with graph-based user behavior signals. The ability to solve this multimodal predictive AI problem is why so many companies combine GNNs with large language model embeddings to achieve the best performance on personalized recommendation tasks.
This lift was achieved in just two weeks of iteration and experimentation by one data scientist because multiple models were trained each day. Building a similar personalized recommendation model architecture from scratch typically takes six to twelve months with teams of machine learning experts.
Path to production
While Kumo supports batch and online options for generating model predictions, the customer chose batch integration, where personalized recommendations are generated on a daily basis and exported to online serving infrastructure.
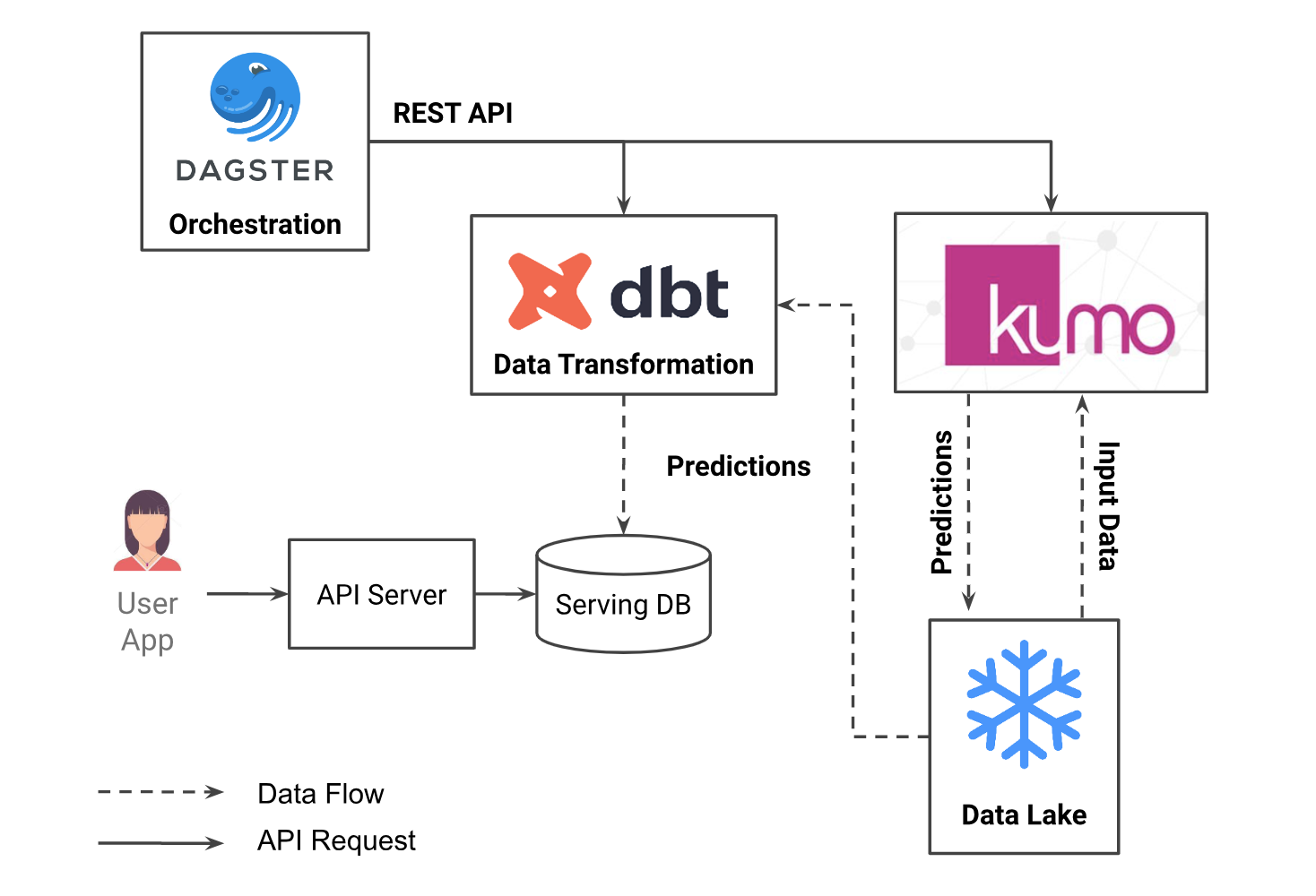
The customer uses Snowflake, DBT, and Dagster for data engineering workflows. Triggering the Kumo job is as simple as calling the Kumo REST API from a Dagster job. Then, Kumo automatically pulls the latest data from the input tables in Snowflake, generates predictions, and writes the result to a new table in Snowflake. The predictions are then read by a downstream DBT job, where they are joined with other tables, re-formatted, and eventually exported to an in-house database for online serving.
The main benefits of this solution are simplicity and velocity. The entire pipeline was developed and deployed by a single data scientist, without needing assistance from the machine-learning-infrastructure team, as would be required for traditional machine learning models.
While the above model is optimized for co-purchase, it will be possible to quickly train new models using Kumo and to run production A/B tests against other objectives, for example re-training the Kumo model to optimize against co-view. By dramatically speeding up the machine learning lifecycle, Kumo enables data scientists to experiment with many different problem formulations to deliver more business impact, while spending less time on lower value, tedious manual work like feature engineering and model design.
Get started with personalized recommendations powered by Kumo AI
Request a demo